
Indizierung von Feldern in Ninox
Indizierung von Felder, die in Abfragen verwendet werden
Nach der Analyse der Performance vieler Ninox-Lösungen zeigt sich, dass zahlreiche Abfragen wiederholt ganze Tabellen durchsuchen, obwohl sie nur eine kleine Anzahl von Ergebnissen zurückgeben.
Typisches Muster:
- Große Tabelle (z. B. 20.000+ Datensätze)
- Abfrage wird hunderte oder tausende Male ausgeführt
- Jede Ausführung durchsucht jede einzelne Zeile
Dies tritt am häufigsten auf, wenn kein Index auf dem gefilterten Feld existiert. Es kann jedoch auch passieren, wenn Abfragen so geschrieben sind, dass eine Indizierung nicht genutzt werden kann.
Dies wirkt sich negativ auf die Performance von Skripten aus, die solche Scans verwenden, und kann zusätzlich die Gesamtleistung der gesamten Lösung sowie der Cloud-Umgebung verschlechtern.
Die Auswirkungen verstärken sich, wenn viele solcher Abfragen in einer Datenbank existieren, und werden zusätzlich erhöht, wenn mehrere Benutzer diese gleichzeitig ausführen.
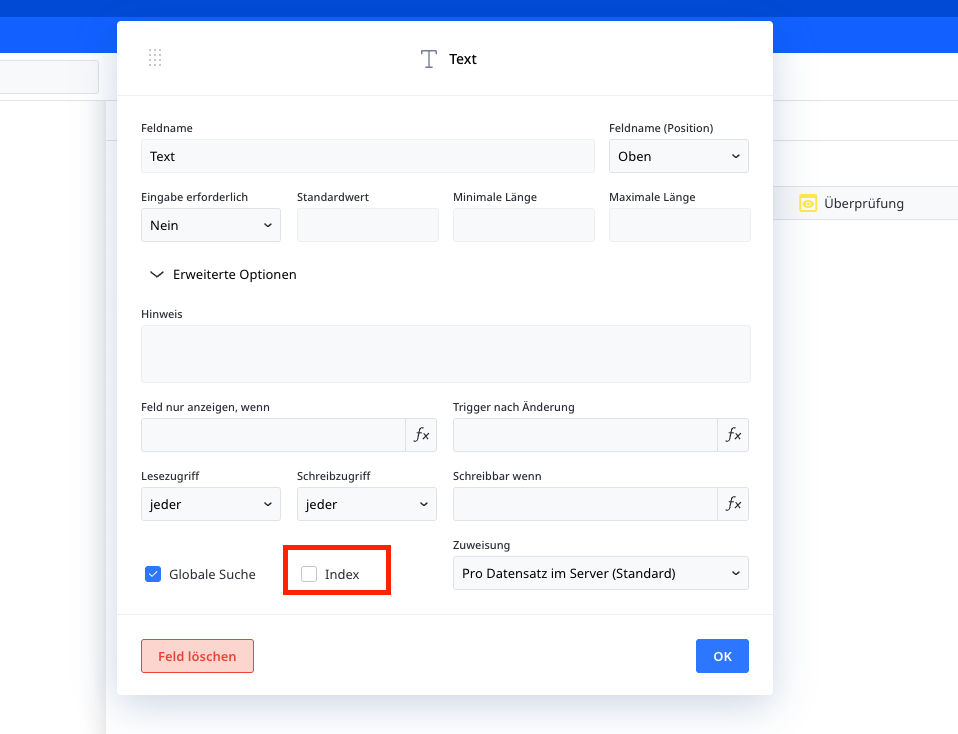
So wenden Sie Indizierung auf ein Feld an
So indizieren Sie ein Feld:
- Öffnen Sie die Tabelle, die Sie abfragen
- Gehen Sie in die Feldeinstellungen
- Aktivieren Sie die Option „Index“
Dies erzeugt eine Lookup-Struktur, mit der die Datenbank Datensätze effizient finden kann.
Wann Indizierung angewendet werden sollte
Wenden Sie Indizierung an, wenn die folgenden Bedingungen erfüllt sind:
- Die Tabelle enthält eine große Anzahl von Datensätzen (tausende oder mehr)
- Das Feld wird in WHERE-Bedingungen (Filtern) in Select-Statements verwendet
- Die Abfrage wird häufig ausgeführt (z. B. in Views, Dashboards, Skripten, Automationen)
Beispiel: Die Tabelle „Tasks“ ist groß und wird häufig für Dashboards abgefragt. Angenommen, es gibt ein Feld „Status“ mit folgenden Werten:

select Tasks where Status = 1Die Indizierung des Feldes „Status“ würde die Performance dieser Abfrage verbessern.
Um die Performance von Dashboards in großen Lösungen mit mehreren gleichzeitigen Benutzern zusätzlich zu stabilisieren, empfiehlt es sich außerdem, Best Practices wie einen clientseitigen Select anzuwenden. Weitere Informationen finden Sie in unserer Performance-Dokumentation.
Geeignete Felder für die Indizierung
- Auswahlfelder, die sehr häufig in Filtern verwendet und enthält eine klar abgegrenzte Menge an Werten:
select Tasks where Status = 1- dynamische Auswahlfelder, die auf Benutzer verweist oder eine dynamische Auswahl darstellt:
select Tasks where AssignedUser = user()
Wann Indizierung vermieden werden sollte
Indizes sollten nicht standardmäßig gesetzt werden, sondern gezielt nur dann, wenn es sinnvoll ist. Sie benötigen zusätzlichen Speicher und erhöhen den Aufwand bei Schreiboperationen, da neue Datensätze ebenfalls indiziert werden müssen.
In folgenden Fällen sollten Sie keine Indizierung anwenden:
- die Tabelle ist klein
- das Feld wird selten gefiltert
- die Abfrage wird selten ausgeführt
- fast alle Datensätze haben denselben Wert
- es gibt nur eine geringe Wertevielfalt (z. B. Ja/Nein-Felder)
Ungeeignete Felder für die Indizierung
- Wenn fast alle Datensätze denselben Wert enthalten:
select Tasks where Country = "DE"- Ja/Nein-Felder mit geringer Wertevielfalt:
select Tasks where IsActive = trueWie Indizierung die Performance verbessert
Betrachten wir ein Beispiel, bei dem das Feld „Status“ nicht indiziert ist, sowie eine weitere Abfrage basierend auf dem zugewiesenen Benutzer:
select Tasks where Status = 1oder
select Tasks where AssignedUser = user()Da kein Index vorhanden ist, wird die Tabelle folgendermaßen abgefragt:
Datensatz 1 laden → Bedingung prüfen
Datensatz 2 laden → Bedingung prüfen
Wiederholung für jeden Datensatz der Tabelle
Bei 20.000 Datensätzen: → 20.000 Auswertungen pro Abfrage
Bei 5.000 Ausführungen: → 100 Millionen Auswertungen
Wenn ein Index vorhanden ist, läuft die Abfrage so ab:
- Suche Status 1 „Open“ im Index
- Abrufen der passenden Datensatz-IDs
- Laden nur dieser Datensätze
Damit wird direkt auf die Ergebnisse zugegriffen, was die Ausführungszeit deutlich reduziert.
Weitere Beispiele
Es gibt weitere Szenarien, in denen Indizierung nicht geeignet ist. Wenn Sie z. B. auf ein Feld eine Funktion anwenden, kann ein Index nicht genutzt werden:
select Tasks where upper(Status) = text("OPEN")
select Tasks where someFunction(Status)In diesen Fällen ist ein vollständiger Scan erforderlich, da zusätzliche Parameter verwendet werden.
Sie können auch auf Szenarien stoßen, in denen es sinnvoll ist, ein vorkalkuliertes Feld einzuführen, das Werte aus mehreren Feldern zusammenführt und effizient indiziert werden kann.
Zum Beispiel filtert die folgende Abfrage Datensätze basierend auf zwei separaten Bedingungen:
select Tasks where not Archived and not AssignedUserEine mögliche Umsetzung wäre, diese Logik in einem vorkalkulierten Ja/Nein-Feld abzubilden. Ein solches Feld wäre jedoch für die Indizierung nicht geeignet, da Ja/Nein-Felder nur zwei mögliche Werte enthalten. Diese geringe Wertevielfalt reduziert die Effektivität der Indizierung und führt in der Praxis nicht zu einer verbesserten Performance.
Stattdessen ist es sinnvoller, ein vorkalkuliertes Feld zu verwenden, das die Kombination dieser Bedingungen in einem eindeutigeren Wert abbildet. Dieses Feld sollte als Textfeld definiert sein und klar unterscheidbare Werte enthalten, ähnlich einem Matchcode.
Beispielsweise könnte ein berechnetes Textfeld (z. B. TaskStatusCode) folgende Werte enthalten:
- active
- archived
- unassigned
- archived_unassigned
Mit diesem Ansatz lautet die Abfrage:
select Tasks where TaskStatusCode = text("active")Da dieses Feld eine höhere Wertevielfalt und klar unterscheidbare Inhalte aufweist, ist die Indizierung deutlich effektiver und kann die Performance von Abfragen spürbar verbessern.